
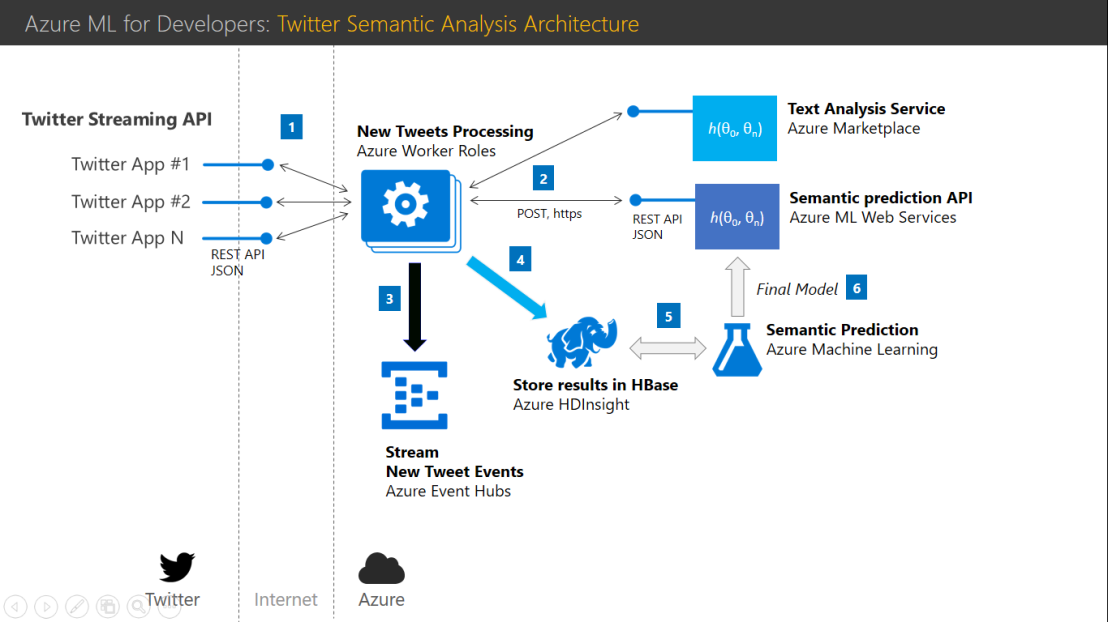
What is machine learning?
Machine learning is a technique of data science that helps computers learn from existing data in order to forecast future behaviors, outcomes, and trends.
These forecasts or predictions from machine learning can make apps and devices smarter. When you shop online, machine learning helps recommend other products you might like based on what you’ve purchased. When your credit card is swiped, machine learning compares the transaction to a database of transactions and helps detect fraud. When your robot vacuum cleaner vacuums a room, machine learning helps it decide whether the job is done.
What is Machine Learning in the Microsoft Azure cloud?
What is predictive analytics?
Azure Machine Learning is a cloud predictive analytics service that makes it possible to quickly create and deploy predictive models as analytics solutions.
You can work from a ready-to-use library of algorithms, use them to create models on an internet-connected PC, and deploy your predictive solution quickly. Start from ready-to-use examples and solutions in the Cortana Intelligence Gallery.
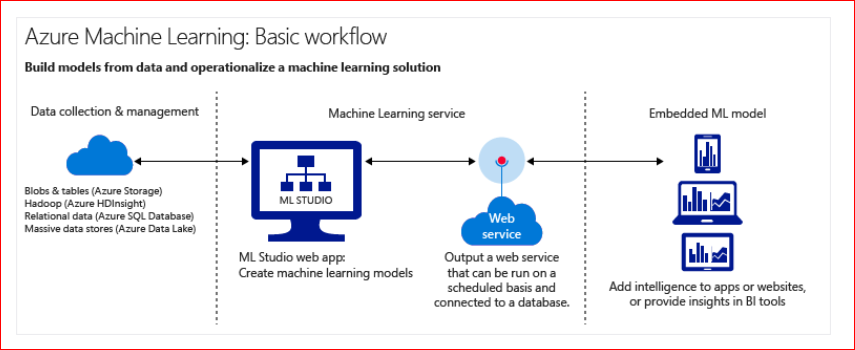 Azure Machine Learning not only provides tools to model predictive analytics, but also provides a fully managed service you can use to deploy your predictive models as ready-to-consume web services.
Azure Machine Learning not only provides tools to model predictive analytics, but also provides a fully managed service you can use to deploy your predictive models as ready-to-consume web services.
What is predictive analytics?
Predictive analytics uses math formulas called algorithms that analyze historical or current data to identify patterns or trends in order to forecast future events.
Tools to build complete machine learning solutions in the cloud
Azure Machine Learning has everything you need to create complete predictive analytics solutions in the cloud, from a large algorithm library, to a studio for building models, to an easy way to deploy your model as a web service. Quickly create, test, operationalize, and manage predictive models.
Operationalize predictive analytics solutions by publishing your own
The following tutorials show you how to operationalize your predictive analytics models:
- Deploy web services
- Retrain models through APIs
- Manage web service endpoints
- Scale a web service
- Consume web services
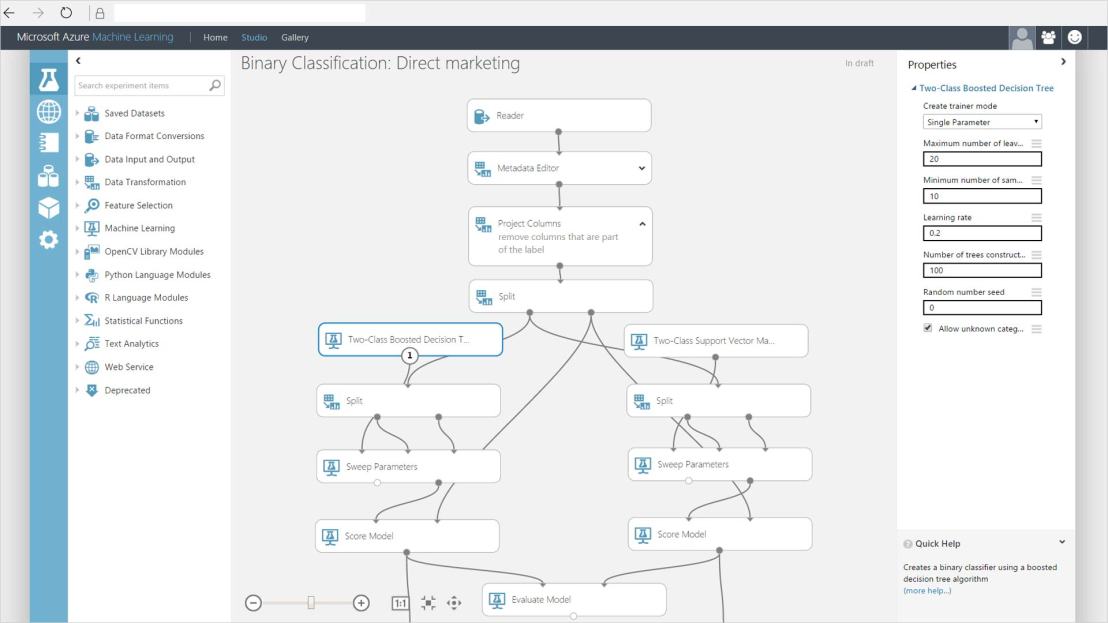
The Machine Learning Studio interactive workspace
To develop a predictive analysis model, you typically use data from one or more sources, transform and analyze that data through various data manipulation and statistical functions, and generate a set of results. Developing a model like this is an iterative process. As you modify the various functions and their parameters, your results converge until you are satisfied that you have a trained, effective model.
Azure Machine Learning Studio gives you an interactive, visual workspace to easily build, test, and iterate on a predictive analysis model. You drag-and-drop datasets and analysis modulesonto an interactive canvas, connecting them together to form an experiment, which you run in Machine Learning Studio. To iterate on your model design, you edit the experiment, save a copy if desired, and run it again. When you’re ready, you can convert your training experiment to a predictive experiment, and then publish it as a web service so that your model can be accessed by others.
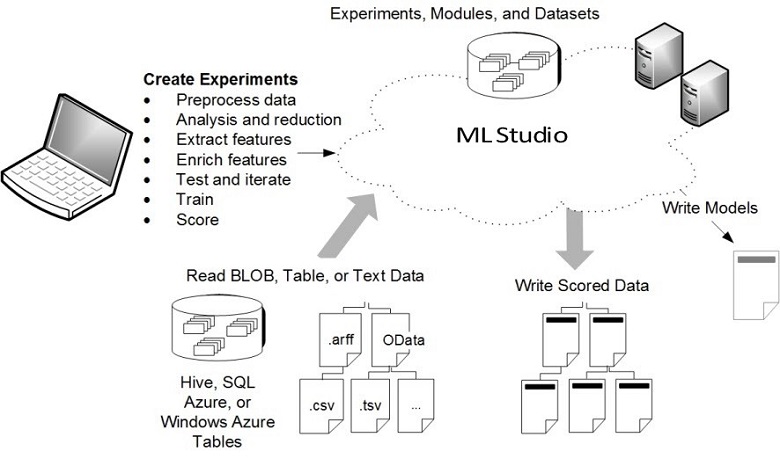
Key machine learning terms and concepts
Machine learning terms can be confusing. Here are definitions of key terms to help you. Use comments following to tell us about any other term you’d like defined.
Data exploration, descriptive analytics, and predictive analytics
Data exploration is the process of gathering information about a large and often unstructured data set in order to find characteristics for focused analysis.
Data mining refers to automated data exploration.
Descriptive analytics is the process of analyzing a data set in order to summarize what happened. The vast majority of business analytics – such as sales reports, web metrics, and social networks analysis – are descriptive.
Predictive analytics is the process of building models from historical or current data in order to forecast future outcomes.
Supervised and unsupervised learning
Supervised learning algorithms are trained with labeled data – in other words, data comprised of examples of the answers wanted. For instance, a model that identifies fraudulent credit card use would be trained from a data set with labeled data points of known fraudulent and valid charges. Most machine learning is supervised.
Unsupervised learning is used on data with no labels, and the goal is to find relationships in the data. For instance, you might want to find groupings of customer demographics with similar buying habits.
Model training and evaluation
A machine learning model is an abstraction of the question you are trying to answer or the outcome you want to predict. Models are trained and evaluated from existing data.
Training data
When you train a model from data, you use a known data set and make adjustments to the model based on the data characteristics to get the most accurate answer. In Azure Machine Learning, a model is built from an algorithm module that processes training data and functional modules, such as a scoring module.
In supervised learning, if you’re training a fraud detection model, you use a set of transactions that are labeled as either fraudulent or valid. You split your data set randomly, and use part to train the model and part to test or evaluate the model.
Evaluation data
Once you have a trained model, evaluate the model using the remaining test data. You use data you already know the outcomes for, so that you can tell whether your model predicts accurately.
Other common machine learning terms
- algorithm: A self-contained set of rules used to solve problems through data processing, math, or automated reasoning.
- anomaly detection: A model that flags unusual events or values and helps you discover problems. For example, credit card fraud detection looks for unusual purchases.
- categorical data: Data that is organized by categories and that can be divided into groups. For example a categorical data set for autos could specify year, make, model, and price.
- classification: A model for organizing data points into categories based on a data set for which category groupings are already known.
- feature engineering: The process of extracting or selecting features related to a data set in order to enhance the data set and improve outcomes. For instance, airfare data could be enhanced by days of the week and holidays. See Feature selection and engineering in Azure Machine Learning.
- module: A functional part in a Machine Learning Studio model, such as the Enter Data module that enables entering and editing small data sets. An algorithm is also a type of module in Machine Learning Studio.
- model: A supervised learning model is the product of a machine learning experiment comprised of training data, an algorithm module, and functional modules, such as a Score Model module.
- numerical data: Data that has meaning as measurements (continuous data) or counts (discrete data). Also referred to as quantitative data.
- partition: The method by which you divide data into samples. See Partition and Sample for more information.
- prediction: A prediction is a forecast of a value or values from a machine learning model. You might also see the term “predicted score.” However, predicted scores are not the final output of a model. An evaluation of the model follows the score.
- regression: A model for predicting a value based on independent variables, such as predicting the price of a car based on its year and make.
- score: A predicted value generated from a trained classification or regression model, using the Score Model module in Machine Learning Studio. Classification models also return a score for the probability of the predicted value. Once you’ve generated scores from a model, you can evaluate the model’s accuracy using the Evaluate Model module.
- sample: A part of a data set intended to be representative of the whole. Samples can be selected randomly or based on specific features of the data set.
Get started with Machine Learning Studio
When you first enter Machine Learning Studio you see the Home page. From here you can view documentation, videos, webinars, and find other valuable resources.
Cortana Intelligence
Click Cortana Intelligence and you’ll be taken to the home page of the Cortana Intelligence Suite. The Cortana Intelligence Suite is a fully managed big data and advanced analytics suite to transform your data into intelligent action. See the Suite home page for full documentation, including customer stories.
Azure Machine Learning
There are two options here, Home, the page where you started, and Studio.
Click Studio and you’ll be taken to the Azure Machine Learning Studio. First you’ll be asked to sign in using your Microsoft account, or your work or school account. Once signed in, you’ll see the following tabs on the left:
- PROJECTS – Collections of experiments, datasets, notebooks, and other resources representing a single project
- EXPERIMENTS – Experiments that you have created and run or saved as drafts
- WEB SERVICES – Web services that you have deployed from your experiments
- NOTEBOOKS – Jupyter notebooks that you have created
- DATASETS – Datasets that you have uploaded into Studio
- TRAINED MODELS – Models that you have trained in experiments and saved in Studio
- SETTINGS – A collection of settings that you can use to configure your account and resources.
Gallery
Click Gallery and you’ll be taken to the Cortana Intelligence Gallery. The Gallery is a place where a community of data scientists and developers share solutions created using components of the Cortana Intelligence Suite.
For more information about the Gallery, see Share and discover solutions in the Cortana Intelligence Gallery.
Components of an experiment
An experiment consists of datasets that provide data to analytical modules, which you connect together to construct a predictive analysis model. Specifically, a valid experiment has these characteristics:
- The experiment has at least one dataset and one module
- Datasets may be connected only to modules
- Modules may be connected to either datasets or other modules
- All input ports for modules must have some connection to the data flow
- All required parameters for each module must be set
You can create an experiment from scratch, or you can use an existing sample experiment as a template. For more information, see Use sample experiments to create new experiments.
For an example of creating a simple experiment, see Create a simple experiment in Azure Machine Learning Studio.
For a more complete walkthrough of creating a predictive analytics solution, see Develop a predictive solution with Azure Machine Learning.
Datasets
A dataset is data that has been uploaded to Machine Learning Studio so that it can be used in the modeling process. A number of sample datasets are included with Machine Learning Studio for you to experiment with, and you can upload more datasets as you need them. Here are some examples of included datasets:
- MPG data for various automobiles – Miles per gallon (MPG) values for automobiles identified by number of cylinders, horsepower, etc.
- Breast cancer data – Breast cancer diagnosis data.
- Forest fires data – Forest fire sizes in northeast Portugal.
As you build an experiment you can choose from the list of datasets available to the left of the canvas.
For a list of sample datasets included in Machine Learning Studio, see Use the sample data sets in Azure Machine Learning Studio.
Modules
A module is an algorithm that you can perform on your data. Machine Learning Studio has a number of modules ranging from data ingress functions to training, scoring, and validation processes. Here are some examples of included modules:
- Convert to ARFF – Converts a .NET serialized dataset to Attribute-Relation File Format (ARFF).
- Compute Elementary Statistics – Calculates elementary statistics such as mean, standard deviation, etc.
- Linear Regression – Creates an online gradient descent-based linear regression model.
- Score Model – Scores a trained classification or regression model.
As you build an experiment you can choose from the list of modules available to the left of the canvas.
A module may have a set of parameters that you can use to configure the module’s internal algorithms. When you select a module on the canvas, the module’s parameters are displayed in the Properties pane to the right of the canvas. You can modify the parameters in that pane to tune your model.
For some help navigating through the large library of machine learning algorithms available, see How to choose algorithms for Microsoft Azure Machine Learning.
Deploying a predictive analytics web service
Once your predictive analytics model is ready, you can deploy it as a web service right from Machine Learning Studio. For more details on this process, see Deploy an Azure Machine Learning web service.
that’s all for now.., any Doubts type a commend.. 🙂
